
Das Problem ist weit verbreitet überall dort, wo Produkte für regulierte Märkte entwickelt werden, z.B. in der Automobilindustrie. Zusätzlich zum Anforderungskatalog des Auftraggebers wird die Erfüllung von Vorgaben aus Mitgeltenden Unterlagen als verbindlich im Vertrag festgeschrieben. Das Problem: diese Mitgeltenden Unterlagen umfassen eine Fülle von Regularien und Vorschriften, oft mehrere Dokumente in unterschiedlichen Formaten, von denen nur eine Teilmenge für das konkrete Projekt relevant ist. Der Auftragnehmer hat zwei Möglichkeiten: entweder er beschäftigt viele Mitarbeiter mit dem akribischen Scannen aller Mitgeltenden Unterlagen, um die relevanten Vorgaben herauszufiltern, oder er geht das Risiko einer Vertragsstrafe ein, wenn nicht alle Vorgaben erfüllt werden.
Seit einiger Zeit gibt es eine dritte Möglichkeit: die Nutzung von KI. Allerdings liefern klassische KI-Systeme hier oft nur den nächsten Treffer, aber keine vollständige und reproduzierbare Antwort. Gemeinsam mit unserem Partner IMS haben wir eine KI-gestützte Methode entwickelt, die mit Hilfe von struktureller Aufbereitung der Mitgeltenden Unterlagen belastbare und Evidenz-basierte Antworten liefert, die das Risiko für den Auftragnehmer minimieren.
Das Problem mit „Treffern"
Ein klassisches Retrieval-System liefert die Textstelle, die semantisch am nächsten an der Frage liegt. Das funktioniert gut bei einfachen, kontextfreien Abfragen. Bei Mitgeltenden Unterlagen versagt dieser Ansatz systematisch: Die relevante Antwort ergibt sich häufig erst aus der Kombination mehrerer Quellen – einem Absatz in Kapitel 3, einer Tabelle in Anhang B und einer Ausnahmeregel, die drei Seiten weiter steht. Wer nur den nächsten Treffer zurückgibt, liefert nur eine halbe Antwort. Wenn es um die Einhaltung von Entwicklungsverträgen und die Vermeidung von Vertragsstrafen geht, ist eine halbe Antwort keine Antwort.
Bessere Struktur statt größere Modelle
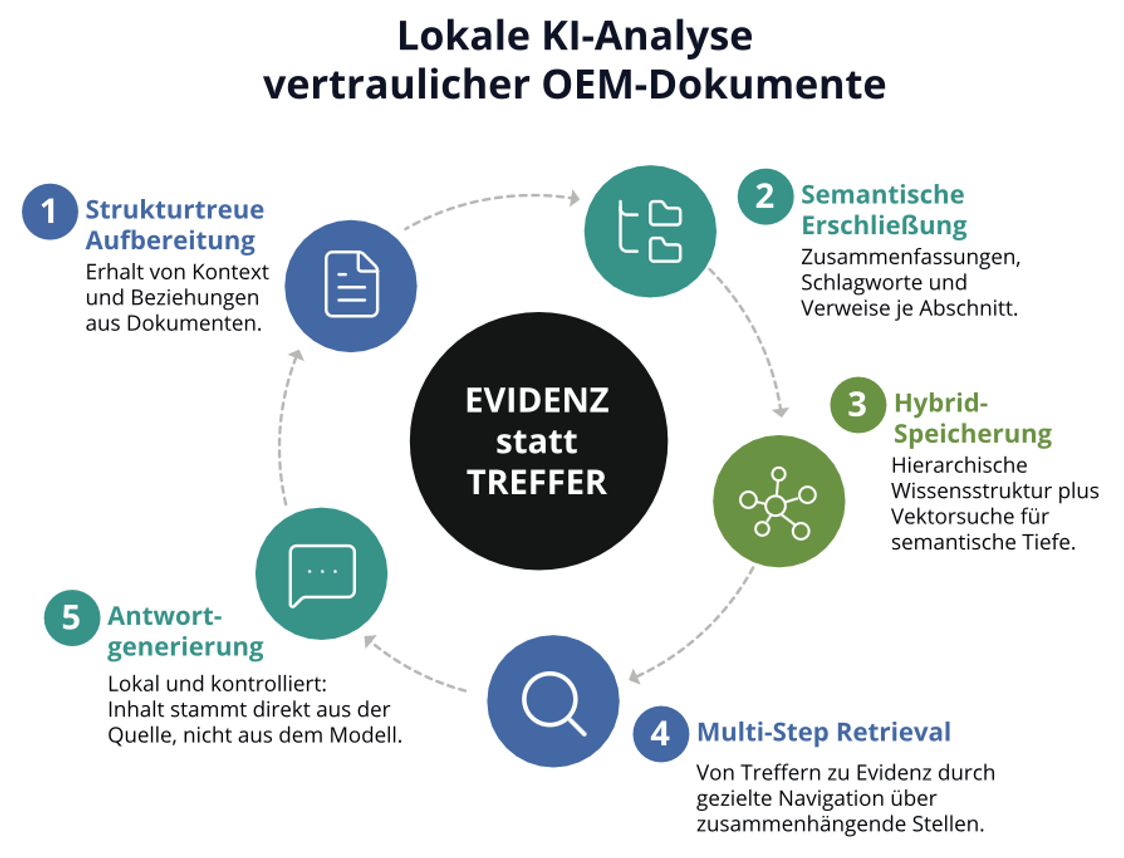
Gemeinsam mit unserem Partner IMS haben wir einen Ansatz entwickelt, der genau hier ansetzt. Der Unterschied beginnt bereits bei der Aufbereitung der zu untersuchenden Informationen: Statt Dokumente blind in Textschnipsel zu zerschneiden, wird jedes Dokument in eine navigierbare, hierarchische Wissensstruktur überführt – der Kontext bleibt erhalten: Kapitelzugehörigkeit, Tabellenstruktur, Geltungs- und Ausnahmebezüge. Jede Stelle wird zusammengefasst, mit Schlagworten und auffindbaren Bezeichnern versehen und zusammenhängende Stellen werden untereinander verlinkt.
Das verändert die Art, wie gesucht wird. Statt einmal zu suchen und das nächstbeste Ergebnis zurückzugeben, arbeitet sich der Assistent gezielt durch die zusammenhängenden Stellen – sucht grob, navigiert in die Struktur, folgt internen Verweisen und lädt den Volltext erst dort nach, wo er ihn braucht. Das Ergebnis ist nicht der wahrscheinlichste Treffer – sondern nachvollziehbare, belegbare Evidenz.
Belegt statt erfunden
Der entscheidende Unterschied steckt im Detail: Der eigentliche Antworttext stammt direkt aus dem Quelldokument, nicht aus dem Sprachmodell. Das Modell erschließt die Struktur – Zusammenfassungen, Schlagworte, Verweise –, aber es formuliert keine Antworten neu. Wo Inhalte vollständig regelbasiert aufbereitet werden können, etwa bei strukturierten Plandaten, entsteht das Ergebnis sogar ganz ohne Sprachmodell: reproduzierbar, sofort, ohne Halluzination – eine höchst wertvolle Eigenschaft für jeden, der mit Normen, Vorschriften und Prüfdokumentation arbeitet.
Lokal, kontrolliert, vertraulich
Für viele OEMs wird Datensouveränität als selbstverständlich vorausgesetzt. Der gesamte Ansatz ist lokal lauffähig – auf eigener Infrastruktur oder in einer privaten Cloud – und nutzt Open-Weights-Modelle wie Qwen. Alle Daten bleiben lokal, verlassen nicht das Unternehmen. Jede Antwort ist mit Quellen (Kapitel, Seite, Tabelle) belegt und in ihrer Herleitung transparent. Das schafft Vertrauen – nicht nur beim Nutzer, sondern auch gegenüber internen Auditoren und externen Prüfern.
Was das in der Praxis bedeutet
Ein Entwickler fragt:
„Gilt die Anforderung aus Abschnitt 4.3 auch für Zulieferteile der Kategorie B?" – und bekommt nicht einfach den Absatz, der „Kategorie B" enthält. Der Assistent navigiert durch das Dokument, zieht die relevante Tabelle, die zugehörige Ausnahmeregelung und den Geltungsbereich des Kapitels heran und setzt sie zu einer belegten Antwort zusammen – jeweils mit Verweis auf die Stelle, aus der sie stammt.
JAIMS als Plattform
Die technische Grundlage liefert JAIMS.ai – eine KI-Assistenzplattform, die speziell für den Einsatz in komplexen, dokumentenintensiven Unternehmensumgebungen entwickelt wurde. SodiusWillert setzt JAIMS für die Analyse Mitgeltender Unterlagen ein und baut darauf einen Assistenten, der nicht nur einzelne Informationselemente als „Treffer“ findet, sondern belastbar und reproduzierbar im Kontext zur Verfügung stellt.
Kontaktieren Sie uns gern mit Ihren individuellen Fragen über unser Kontaktformular. Für einen ersten Eindruck von JAIMS empfehlen wir auch die Website jaims.ai.
Oder laden Sie sich für einen short overview den Flyer herunter


Leave us your comment